
How MySQL Preserves Consistency: Transactions, Locks, MVCC, and Logs
Covers transactions, locks, MVCC, logs, and related optimization notes.
MySQL Transactions, Locks, MVCC, and Logs#
Transactions#
ACID Properties#
The ACID properties and how they are guaranteed.
- Atomicity: Guaranteed by undo log.
- Consistency: Guaranteed by the other three properties.
- Isolation: Guaranteed by locking mechanisms / MVCC.
- Durability: Guaranteed by redo log.
Transaction Isolation Levels#
- Read Uncommitted: Changes made by a transaction before it commits can be seen by other transactions.
- Read Committed: Changes made by a transaction can only be seen by other transactions after it commits.
- Repeatable Read: Data seen during a transaction’s execution is consistent with the data seen when the transaction started. This is the default isolation level for MySQL’s InnoDB engine.
- Serializable: Acquires read and write locks on records. When multiple transactions perform read/write operations on a record and a read-write conflict occurs, subsequent transactions must wait for the previous transaction to complete before continuing execution.
Generally speaking, using Repeatable Read (the default) can largely avoid phantom read issues (though they can still occur). The Serializable isolation level impacts performance. Phantom reads are basically resolved through the following two methods:
- For ordinary SELECT statements (snapshot reads), MVCC resolves phantom reads.
- For SELECT…FOR UPDATE statements (current reads), next-key locks (record lock + gap lock) resolve phantom reads.
Implementation methods:
- For the Read Uncommitted isolation level, because uncommitted changes from other transactions can be read, the latest data is read directly.
- For the Serializable isolation level, concurrent access is prevented by adding read/write locks.
- For the Read Committed and Repeatable Read isolation levels, they are implemented using Read Views. Their difference lies in when the Read View is created. Think of a Read View as a data snapshot, like a camera capturing the scenery at a specific moment. The Read Committed isolation level re-generates a Read View before each statement execution, whereas the Repeatable Read isolation level generates a Read View when the transaction starts and uses it throughout the entire transaction.
Commands to start a transaction in MySQL:
BEGIN/START TRANSACTION: The transaction is not truly considered started until the first SELECT statement is executed.START TRANSACTION WITH CONSISTENT SNAPSHOT: Starts the transaction immediately.
Dirty Read / Non-repeatable Read / Phantom Read#
- Dirty Read: A transaction reads data that has been modified by another uncommitted transaction.
- Non-repeatable Read: In the same transaction, reading the same data multiple times results in different values.
- Phantom Read: In the same transaction, querying the number of records that meet a certain condition multiple times results in different counts.
MVCC (Important)#
How does Read View work in MVCC?
Read View:
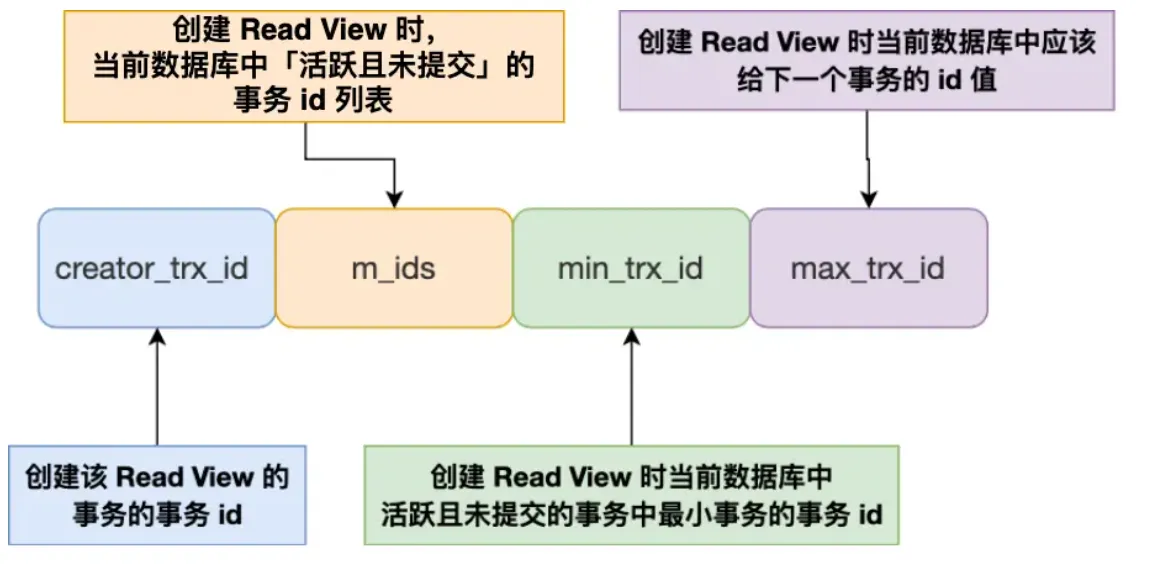
After creating a Read View, the record’s trx_id falls into one of these three categories:
This method of controlling concurrent transaction access to the same record through a “version chain” is called MVCC (Multi-Version Concurrency Control).
Simply put, the MVCC logic chain can be remembered like this:
- Each row record carries
trx_idandroll_pointer. trx_idindicates the transaction ID that last modified this row.roll_pointerpoints from the current version to the previousundo logversion.- Thus, a record forms a version chain through
undo logs. - During a snapshot read, a transaction uses its own
Read Viewto traverse the version chain backwards until it finds a version visible to it.
Add a few points most likely to be asked in follow-up questions from Apple Notes:
undo logis not just for rollback; it’s also the true source of MVCC historical versions.- For
DELETE, InnoDB does not physically delete immediately. It first marks the record for deletion, which is later cleaned up by thepurgethread. - For
UPDATE:- If the primary key column is updated, it’s essentially treated as “delete old row + insert new row”.
- If a non-primary key column is updated, the old value is recorded in the
undo log. During rollback or snapshot reads, the historical version can be accessed along the version chain.
undo pagesthemselves also go into theBuffer Pool. True persistence still relies onredo logas the fallback.
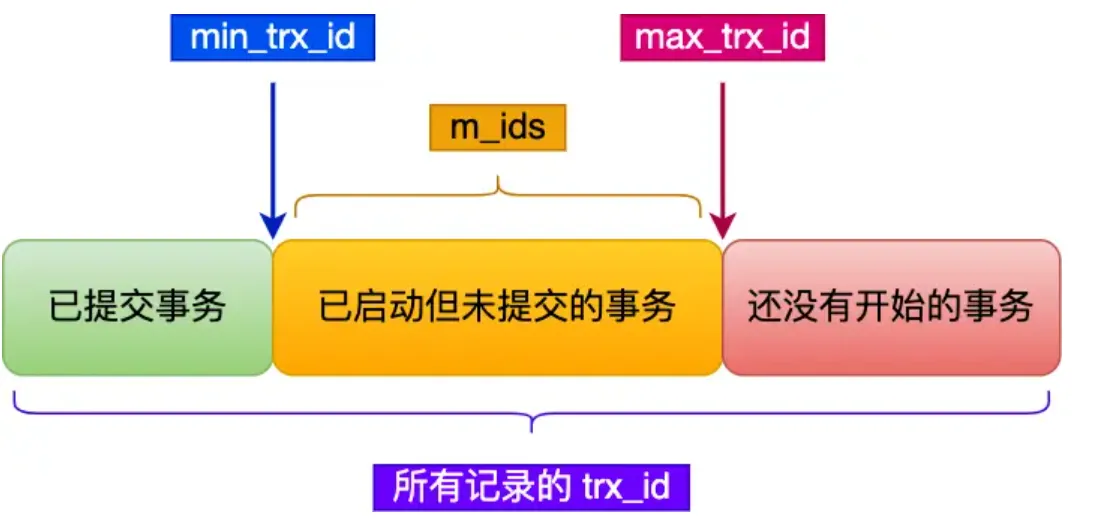
Read View Visibility Determination#
trx_id < min_trx_id: The transaction that modified this version had already committed when the snapshot was created. The current version is visible.trx_id >= max_trx_id: This transaction ID was assigned after the snapshot was created. The current version is not visible; need to look for an older version.min_trx_id <= trx_id < max_trx_id:- If
trx_idis in the list of active transactions, it means this transaction hadn’t committed when the snapshot was taken. The version is not visible. - Otherwise, the transaction had already committed, so the version is visible.
- If
How does MVCC implement Read Committed / Repeatable Read?#
For Read Committed:
- A new Read View is regenerated before each SELECT statement execution.
For Repeatable Read:
- A Read View is generated when the transaction starts (upon the first SELECT or BEGIN), and this Read View remains valid throughout the entire transaction lifecycle without being regenerated.
In which scenario can MVCC not completely prevent phantom reads?#
## Transaction A-----------------
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t_stu where id = 5;
Empty set (0.01 sec)
## Transaction B-----------------
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t_stu values(5, 'Xiaomei', 18);
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
## Transaction A-----------------
mysql> update t_stu set name = 'Xiaolin Coding' where id = 5;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from t_stu where id = 5;
+----+----------------+------+
| id | name | age |
+----+----------------+------+
| 5 | Xiaolin Coding | 18 |
+----+----------------+------+
1 row in set (0.00 sec)Attention: The main reason is that MVCC only supports SELECT. It’s ineffective when UPDATE is involved…
However, phantom reads can be completely resolved using MVCC + next-key lock!
The InnoDB storage engine resolves phantom reads at the RR level through MVCC and Next-key Lock:
-
Executing ordinary SELECT: Data is read using MVCC snapshot reads. In snapshot reads, the RR isolation level generates a Read View only upon the first query in the transaction and uses it until the transaction commits. Therefore, updates and inserts made by other transactions after the Read View is generated are not visible to the current transaction, achieving repeatable reads and preventing “phantom reads” under snapshot reads.
-
Executing current reads like
SELECT...FOR UPDATE / LOCK IN SHARE MODE,INSERT,UPDATE,DELETE: Under current reads, the latest data is always read. If another transaction inserts a new record that falls within the current transaction’s query scope, a phantom read would occur! InnoDB uses Next-key Lock to prevent this. When a current read is executed, it locks the records that are read and also locks the gaps between them, preventing other transactions from inserting data within the query scope. Preventing insertion prevents phantom reads.
graph TD
MVCC[MVCC Mechanism] --> UndoLog[Undo Log Version Chain]
MVCC --> ReadView[ReadView Consistent View]
UndoLog --> |Constructs historical versions| RowVersions[Row Multi-Version Chain]
ReadView --> |Determines visibility| Visibility[Data Visibility Rules]
RowVersions --> Row1[Current Version: trx_id=200]
RowVersions --> Row2[Historical Version 1: trx_id=150]
RowVersions --> Row3[Historical Version 2: trx_id=100]
ReadView --> RV1[Active Transaction List: 180,220]
ReadView --> RV2[Minimum Active Transaction ID: 180]
ReadView --> RV3[Maximum Allocated Transaction ID: 250]Locking Mechanism#
- Global Locks
- Table-level Locks
- Table Locks
- Metadata Locks (MDL)
- Intention Locks
- AUTO-INC Locks
- Row-level Locks
- Record Lock: Locks a single index record.
- Gap Lock: Locks a gap between index records (open interval).
- Next-Key Lock: Combination of Gap Lock and Record Lock (usually seems to be left-open, right-closed).
- Insert Intention Lock
The previous explanation from Gemini was quite good.
Usage Scenarios#
This section directly brings back the lock details from Apple Notes, focusing on: How Record Lock, Gap Lock, and Next-Key Lock are applied for different index types + equality/range queries.
First, remember the command to observe locks:
select * from performance_schema.data_locks\G;- Unique Index Equality Query
- Record exists:
next-key lockdegenerates into arecord lock. - Record does not exist: Degenerates into a
gap lock. Because locks are placed on indexes, a non-existent record itself cannot be record-locked.
- Record exists:
- Unique Index Range Query
id > target: Scans to the right using next-key intervals like(target, next]. The final segment might become(last, +∞].id >= target: The starting point might first degrade to a record lock, but subsequent intervals are still locked according to the range.id < target/id <= target: Key point is whether the right boundary crosses the query’s upper bound. Once crossed, the final segment often degrades to a gap lock, as the main goal is to prevent phantom reads caused by inserts within the interval.
- Non-Unique Index Equality Query
- This usually locks not only the matched records but also adds gap/next-key locks.
- Typical reason: If only the currently matched rows are locked, a new record with the same index value but a different primary key could still be inserted, changing the result set on the next query.
- The note’s example
age = 22 for updatedemonstrates a combination: a next-key lock for(21,22], a gap lock for(22,39), and record locks on the primary keys of the matched rows.
- Non-Unique Index Range Query
next-key lockgenerally does not degrade easily. The core goal is to ensure “re-querying this range yields the same result set”.
- Query Without an Index
- Leads to a full table scan. All records encountered along the way are locked.
UPDATE/DELETEwithout an index behave the same. Therefore, such statements are both slow and tend to significantly widen the lock scope.
- Leads to a full table scan. All records encountered along the way are locked.
Deadlock Supplement#
The deadlock example mentioned in Apple Notes essentially illustrates the conflict between gap locks and insert intention locks.
gap lockandgap lockdo not conflict with each other.- However, if two transactions both acquire a gap lock on a certain interval and then each tries to insert data into that interval, they will request an
insert intention lock. - The insert intention lock conflicts with the gap lock held by the other transaction. Thus, both wait for each other, creating a deadlock.
So, for this question, don’t just say “a deadlock occurred”. Explain more clearly:
- Why could they coexist during the query phase?
- Why did they block each other once the insertion phase started?
- Why does InnoDB eventually have to roll back one of the transactions?
Logs#
- redo log
- binlog
- undo log
- Buffer pool
- …
For this part, Heima’s video content seems decent and can be referenced.
undo log#
- Inserting a record: Records the primary key value. For rollback, simply delete this inserted record.
- Deleting a record: First marks it for deletion while retaining the old record information. For rollback, restore the record. Actual physical deletion is handled by the
purgethread. - Updating a record:
- Updating a primary key column is essentially treated as “delete old row + insert new row”.
- Updating a non-primary key column logs the old value, allowing a reverse update during rollback.
undo log is a logical log.
Functions:
- Guarantees transaction atomicity, enabling transaction rollback.
- Implements MVCC via
Read View + undo log. - Chains historical versions using
trx_id + roll_pointer.
Buffer Pool#
The cache pool.
One of the core structures that handles read/write performance in the InnoDB engine.
- When reading data, if the data page is already in the buffer pool, it’s read directly from memory.
- When modifying data, the in-memory page is updated first, and the page is marked as “dirty”.
- Dirty pages are not flushed to disk immediately. A background thread writes them back to disk at an appropriate time.
Common scenarios triggering dirty page flush:
- The
redo logis almost full. Buffer Poolspace is low, requiring dirty page eviction.- A background thread performs periodic flushing.
- Before MySQL shuts down normally, it tries to flush dirty pages as much as possible.
Apple Notes also added a few often-overlooked structures:
- free list: Quickly obtain an available clean cache page without scanning the entire memory area.
- flush list: Strings dirty pages together separately, allowing the background thread to traverse directly when flushing.
- LRU list: Manages hot and cold pages.
Moreover, InnoDB doesn’t use a simple LRU; it divides the LRU list into young and old regions:
- Solves read-ahead failure: Pages brought in by read-ahead are first placed in the
oldregion, preventing them from immediately occupying hot spots. - Solves Buffer Pool pollution: Pages from large scans must spend enough time in the
oldregion before qualifying for promotion toyoung.
The Buffer Pool contains not just data pages, but also:
- Data pages
- Index pages
- Insert buffer pages
- undo pages
- Adaptive hash index
- Lock information
When querying a single record, InnoDB doesn’t just load that one row; it loads the entire page into the cache, then locates the record via the page directory.
redo log#
To prevent data loss during a power failure, InnoDB uses WAL (Write-Ahead Logging):
- First, update the in-memory page.
- Concurrently, write the page modification as a
redo logentry. - Later, at an appropriate time, flush the dirty page back to disk.
redo log is a physical log: It records “which tablespace, which page, which offset, was changed to what value”.
Its two core values are:
- Crash recovery: Can redo the modifications of committed transactions that hadn’t been flushed to disk yet.
- Provides durability guarantees for in-memory modifications like
undo pagesand data pages.
Points often discussed alongside redo log:
redo log buffer: Buffers log entries in memory to reduce frequent disk flushes.page cache: The operating system’s filesystem page cache.innodb_flush_log_at_trx_commit: Controls the flush strategy at transaction commit time.
binlog#
binlog belongs to the MySQL Server layer, not the InnoDB layer.
It is a logical log, commonly used for:
- Master-slave replication.
- Point-in-time recovery.
- Auditing changes.
In an interview, explaining these points is usually sufficient:
redo loghandles crash recovery and ensures InnoDB durability.binlogrecords “what this change did” for the MySQL Server layer’s use.
Why the Two-Phase Commit for redo log and binlog?#
If only one log were written before committing, problems would occur:
redo logexists,binlogmissing: The master can recover, but master-slave replication would lose the transaction.binlogexists,redo logmissing: A slave might have applied this change, but if the master crashes and recovers, it might miss this data.
Therefore, InnoDB uses a two-phase commit:
- Write the
redo logto thePREPAREstate. - Write the
binlog. - Mark the
redo logasCOMMIT.
This way, even if a crash occurs midway, the state of redo log + binlog can be used to determine whether the transaction should be recovered or not.
Optimization!#
JavaGuide:
- Read-Write Separation
- Database/Table Sharding
- Solving Master-Slave Delay
- Conditions warranting sharding
- Data Tiering (Hot/Cold Separation)
- SQL Performance Optimization?
- Disk I/O optimization related to logs (see notes)
- Caching Mechanisms?