Raft Summary
A study note on Raft covering replicated state machines, elections, log replication, safety, cluster membership changes, and snapshots.
State machine:
- Has internal state
- Receives commands from outside
- Updates state according to rules, and returns a result
In other words: a system whose internal state evolves according to input commands
Replicated state machines: multiple copies of a state machine that are replicated
The name may seem unintuitive, because it emphasizes an abstract model, not a concrete implementation.
It could also be called a “multi-replica command synchronization system,” but that would be too close to the implementation. “Replicated state machine” better highlights the problem abstraction.
Replicated state machine = many machines, each maintaining the same “business object,” keeping them consistent by executing the same sequence of commands.
Same initial state + same input = same final state
This description might seem intuitive, but intuitiveness doesn’t make it a usable system design model. We may have already taken for granted:
- State machines are deterministic
- Nodes have the same initial state
- Command inputs are the same
- Command order is the same
- Nodes don’t do anything else unexpected in the middle
We need to make this intuition more rigorous, so the rest of the paper can build on it:
That is:
- As long as I ensure log consistency
- Then command order is guaranteed to be consistent
- Then state is guaranteed to be consistent
This is the transformation: distributed consensus problem → replicated state machine problem → log consistency problem
A brief summary of the Raft consensus algorithm from the paper:

State Simplification#
Original diagram from the paper:
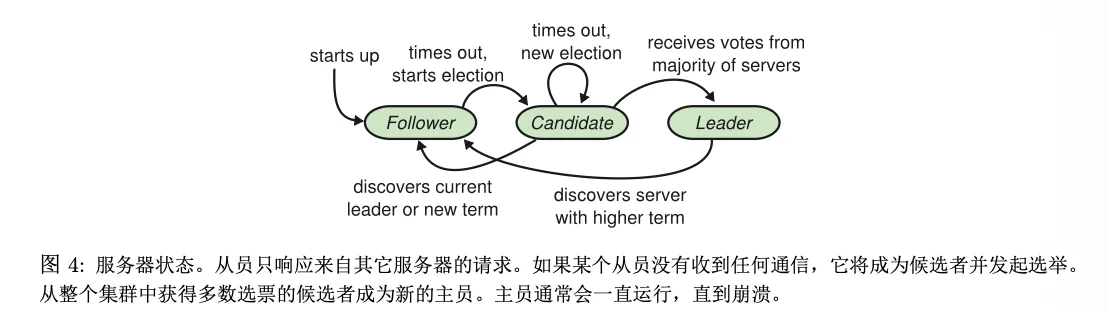
State transitions between the three roles:
- follower: When the election timeout fires, transitions to candidate, then either becomes leader or returns to follower depending on the election outcome
- leader: When the leader sees a message with a higher term than its own, it steps back to follower
- Leader crash: directly goes down; when it recovers, it becomes a follower
- Leader network partition: it may still think it’s the leader, but other nodes in the cluster will time out and elect a new leader; when this old leader later sees the higher term, it steps back to follower
- Beyond the paper, there are various custom implementations for leader resignation
Term: Serves as the timeline in the Raft algorithm. Each term begins with an election! Ensures that the number of leaders elected per term is ≤ 1.
The term helps us confirm a server’s historical state
Servers communicate via RPC in Raft. The two main types of RPC:
- RequestVoteRPC: Sent by candidates during elections
// RequestVote RPC Request
type RequestVoteRequest struct {
term int // current term of the candidate
candidateId int // candidate's ID
lastLogIndex int // index of the candidate's last log entry
lastLogTerm int // term of the candidate's last log entry
}
// RequestVote RPC Response
type RequestVoteResponse struct {
term int // current term of the responder
voteGranted bool // whether the responder votes for this candidate
}- AppendEntriesRPC: Used for log replication
// AppendEntries RPC Request
type AppendEntriesRequest struct {
term int // leader's current term
leaderId int // leader's ID
prevLogIndex int // index of log entry immediately preceding new ones
prevLogTerm int // term of prevLogIndex entry
entries []byte // log entries to store (empty for heartbeat)
leaderCommit int // leader's commitIndex
}
// AppendEntries RPC Response
type AppendEntriesResponse struct {
term int // current term of the follower
success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
}Leader Election#
Heartbeat mechanism: The leader periodically sends heartbeats to all followers to maintain its authority.
- If a follower doesn’t receive heartbeats for a period of time, it assumes there’s no available leader and starts an election:
- The follower increments its current term
- Transitions to candidate state
- Votes for itself and sends RequestVote RPCs to all other servers in parallel
An election can have three outcomes:
- The node wins with votes from a majority → becomes leader, starts sending heartbeats
- Another node wins the election → upon receiving the new leader’s heartbeat (with term ≥ its current term), reverts to follower
- No leader elected → each candidate starts a new election after its own random election timeout
- This happens when multiple followers become candidates simultaneously, splitting the vote so no one gets a majority
If a candidate neither receives a majority of votes nor hears from a new leader, it will start a new election after the random election timeout — this doesn’t require consensus among nodes
Log Replication*#
- After the leader receives a command, it appends the command as a new log entry to its log
- The leader sends AppendEntries RPCs in parallel to followers, asking them to replicate the entry; once the leader confirms the entry has been replicated to a majority of nodes, the log can be committed; after committing, the leader applies it to its state machine and returns the result to the client
Log entry:
- State machine command
- Leader’s term number
- Log index
Both the log index and term are needed to uniquely identify a log entry
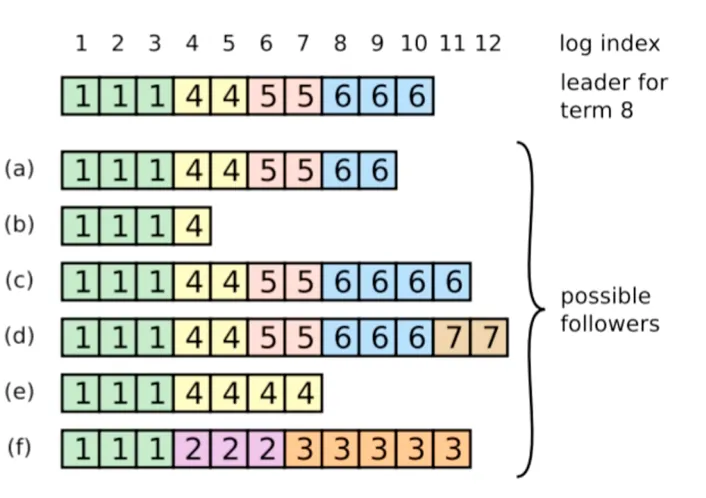
Illustration:
As can be seen from the diagram, some nodes’ logs are far behind. How do we get these nodes to catch up with the leader, so that eventually all nodes have complete and consistent logs?
There are three common cases:
-
Follower is lagging behind The follower is simply slow, not down. The leader keeps sending AppendEntries. If a log entry has been successfully replicated to a majority, the leader can commit and reply to the client; Even if this slow follower hasn’t caught up yet, it doesn’t affect the safety of this committed log. The leader will continue to fill in the missing log entries later.
-
Follower recovers from crash The follower may have missed many log entries after being down for a while. After recovery, it will re-receive the leader’s AppendEntries. If prevLogIndex / prevLogTerm don’t match, it means its current log is inconsistent with the leader; The leader will back off and retry until it finds a common prefix, then append the missing entries from there.
-
Old leader recovers after crash Before crashing, the old leader may have written some uncommitted log entries. These uncommitted entries are not guaranteed to be preserved; if the new leader’s log conflicts with them, the old entries can be overwritten. The old leader will first revert to follower state upon recovery. When it receives the current leader’s AppendEntries, if it finds conflicts, it will delete its conflicting suffix and append the leader’s log, eventually catching up.
Additional note: During the voting phase, the last log entry (lastLogTerm, lastLogIndex) of the candidate is compared. This comparison includes not just committed logs but also uncommitted logs. The purpose is to prevent obviously outdated nodes from being elected. But “log being newer” does not mean “these uncommitted logs will definitely be preserved”; Uncommitted logs could still be overwritten later.
Consistency check: In the AppendEntries RPC sent to a follower, the leader includes the index and term of the log entry immediately preceding the new ones. If the follower cannot find this preceding entry in its log, it rejects the new entry. The leader then retries with the previous log entry, achieving step-by-step backward location of the follower’s first missing log position
Of course, this approach seems inefficient. In theory it can be optimized (the paper mentions optimization ideas), but the author thinks this is unnecessary since such scenarios are rare (in computer applications, there’s often a trade-off, and you can adjust strategies based on requirements)
From the above, we can see: once a leader is elected, there’s no need for a special “log repair process”; the leader just continues sending AppendEntries normally, and followers that are behind or have conflicts will gradually catch up through failed consistency checks and retries
A leader will never overwrite or delete its own log entries to accommodate a follower; but when an old leader later recovers as a follower, its uncommitted and conflicting log suffix may still be overwritten by the current leader
This guarantees:
- As long as a majority of servers can operate normally, Raft can accept, replicate, and apply new log entries
- New log entries can be replicated to a majority of servers in the cluster within one RPC round trip
- A single slow follower does not affect overall performance
For the AppendEntries RPC:
// AppendEntries RPC Request
type AppendEntriesRequest struct {
term int // leader's current term
leaderId int // leader's ID
prevLogIndex int // index of log entry immediately preceding new ones
prevLogTerm int // term of prevLogIndex entry
entries []byte // log entries to store
leaderCommit int // leader's commitIndex
}
// AppendEntries RPC Response
type AppendEntriesResponse struct {
term int // current term of follower
success bool // true if follower contained entry matching prevLogIndex and prevLogTerm
}Here, prevLogIndex and prevLogTerm are used for the consistency check. Only when both match the follower’s log will the follower accept the append; otherwise it rejects, and the leader backs off and retries
For the follower, receiving a log entry from the leader doesn’t mean it can commit immediately, because the follower doesn’t know whether this log entry has reached a majority. Only the leader, after confirming it has reached a majority, notifies the follower to advance its commit through
leaderCommit
leaderCommit: The leader communicates this commit information to followers (via this field in AppendEntries RPC)
The follower can then mark its replicated but uncommitted logs as committed, and apply them to its state machine
If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
This might sound abstract, but in essence: the follower can commit up to
leaderCommitfor the log entries it already has locally. It can’t skip over gaps, and it can’t commit log entries it hasn’t received yet
Safety*#
For leader election and log replication, these two sub-problems already cover the entire consensus algorithm, but they don’t guarantee that every state machine will execute the same commands in the same order. Therefore, Raft needs to supplement and refine the algorithm to handle various crash scenarios without errors.
- Leader crash handling: election restriction
- Leader crash handling: whether a new leader can commit log entries from previous terms
- Follower and candidate crash handling
- Timing and availability limits (already discussed under random timeout)
If a follower lags behind the leader by several log entries and the voting doesn’t compare log freshness, it could be elected as leader in the next election; if such an outdated node becomes leader, it could lead the system down the wrong history. Therefore, Raft must restrict candidate logs during the voting phase from being older than the voter’s.
In the RequestVote RPC, there’s such a restriction: if the voter’s own log is newer than the candidate’s, it will reject the vote request.
How to compare “newer”: Compare lastLogIndex and lastLogTerm. If the terms of the last entries differ, the one with the larger term is “newer.” If the terms are the same, the one with the longer log index is “newer.”
Illustration:
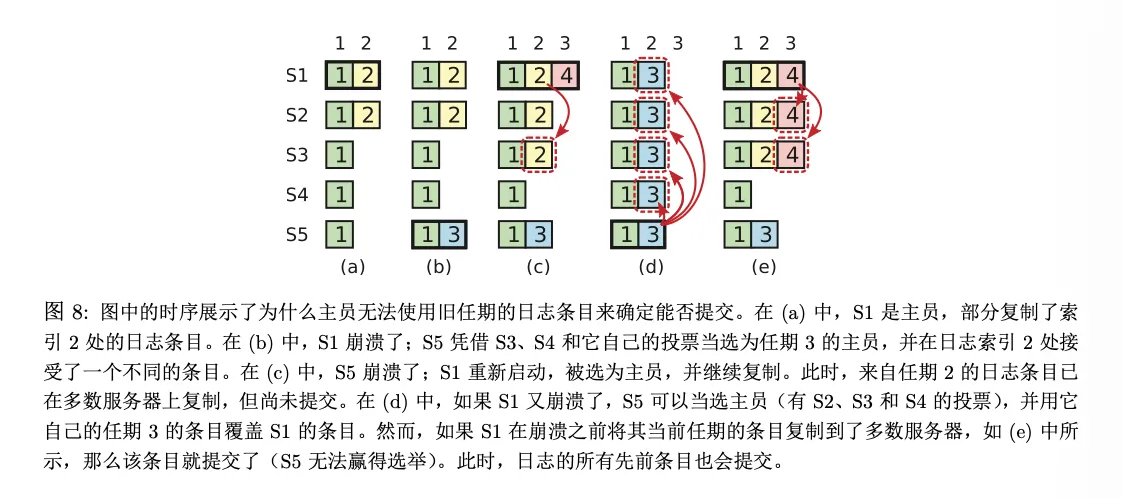
In A, S1 is the leader. Then S1 crashes, and S5 becomes leader. But S5 can still become leader with votes from S3 and S4. At stage B, log entries from term 3 are received. In C, S5 crashes again, S1 becomes leader, and at this point log 2 has been replicated to a majority of nodes, but has not yet been committed. In D, S1 crashes again, and S5 becomes leader with votes from S2-4.
There’s a question: since log 2 here has been replicated to a majority of nodes, yet it can still be overwritten, doesn’t that create a safety issue?
The key point: the diagram doesn’t intend to show “committed logs can also be overwritten,” but rather “a log from an old term, even if present on a majority of nodes, still cannot be considered committed based on that fact alone.”
If an old-term log entry is truly later committed, then any new leader that can be elected must contain it. Committed logs will never be overwritten. What can be overwritten are those not yet committed old-term logs. Therefore:
A leader cannot commit an old-term log based solely on “majority replication”; a leader can only advance commit by having a “current-term log reach a majority.”
And once the current term’s log is committed, the old logs before it are also committed.
On handling follower and candidate crashes:
If a follower or candidate crashes, subsequent RequestVote and AppendEntries RPCs sent to it will fail. Raft handles this through continuous retries. If the crashed machine restarts, these RPCs will eventually succeed. If a server crashes after completing an RPC but before responding, it will receive the same request again after restarting (Raft RPCs are idempotent).
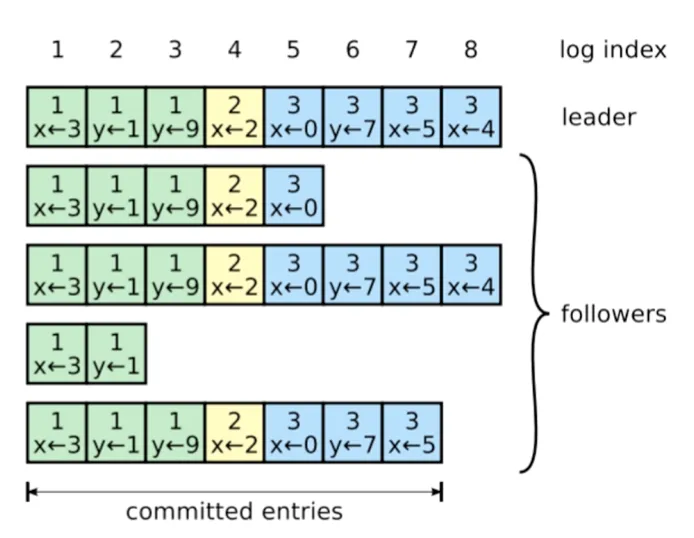
Example#
Consider a scenario with 5 servers. Initially all 5 are followers. S1 times out first, gets the first-mover advantage, and becomes leader. After S1 becomes leader, it sends heartbeats to all servers. Now S1 sends log 1 to S2-5. When S1 receives success responses from a majority, S1 commits locally. Then S1’s next heartbeat conveys this information to the followers, and all nodes commit.
Now we send another request to S1. When S1 receives replies from other machines, it commits locally. Then S1 crashes at this point. The other machines cannot commit log 2.
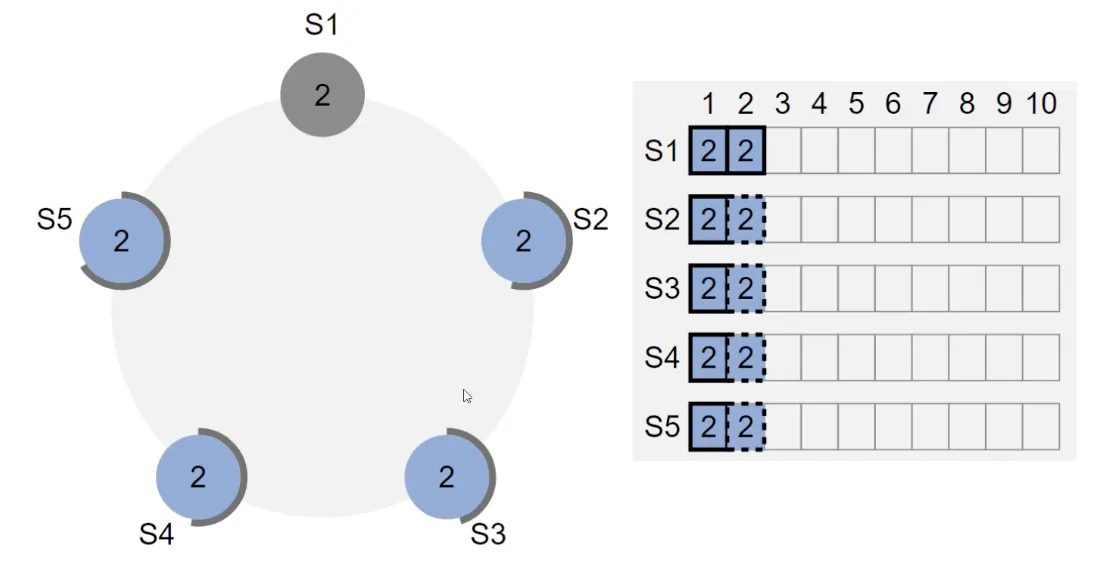
After the election timeout, a new leader S3 is elected. Although S3 keeps sending heartbeats, log 2 still cannot be committed (because S3’s current term is 3, and the leader can only commit logs from the current term by having them reach a majority; for logs from term 2, it can’t commit them directly — they can only be committed together with subsequent logs).
When we send a request to S3, we’ll see that as the new log is committed, the old log is also committed (log 2 and log 3 are committed simultaneously, i.e., their boxes become solid at the same time).
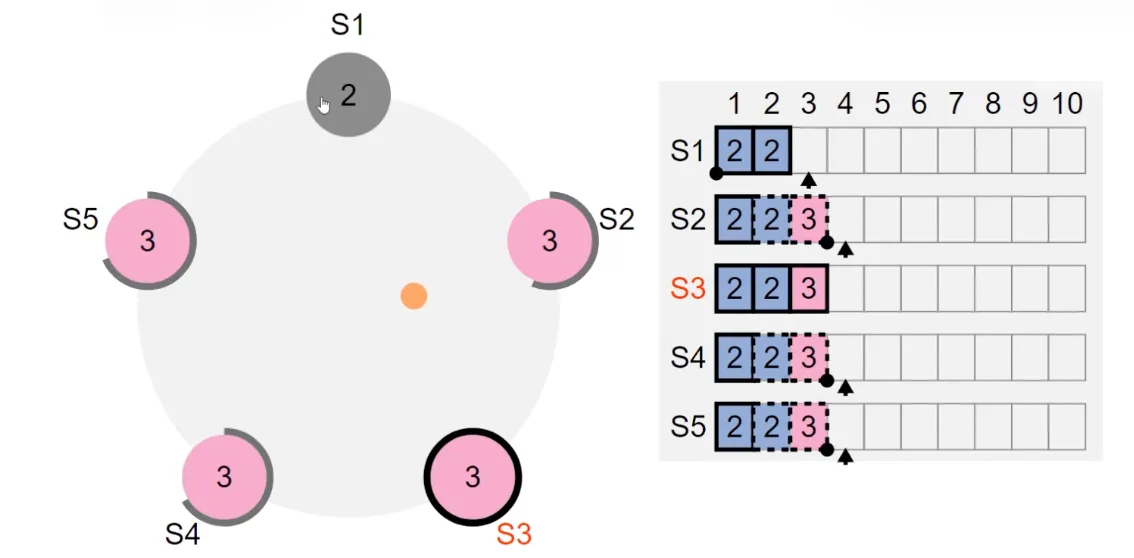
The point is: the current term can only commit logs from the current term. Logs from previous terms can only be committed together when subsequent logs are committed.
Cluster Membership Change#
Multi-Server Change#
For the old-configuration cluster and the new-configuration cluster, there could be a situation with two leaders (split brain). To solve this problem:

A two-phase approach is used: the cluster first transitions from the old configuration to a transitional configuration (joint consensus), then transitions to the new configuration.
So the problem becomes how to avoid split brain in the joint consensus state. Configuration information is packaged as a log entry and sent as a normal AppendEntries RPC to all followers.
- Phase 1: The leader sends
C_old,newto put the entire cluster into joint consensus state. At this point, all RPCs must succeed in a majority of both the old and new configurations to be considered successful. - Phase 2: The leader sends
C_newto put the entire cluster into the new configuration state. At this point, all RPCs need only succeed in a majority of the new configuration.
Once a server adds the new configuration to its log, it uses the latest configuration to make all future decisions. Regardless of whether the configuration has been committed, a server always uses the latest configuration in its log. This means the leader doesn’t need to wait for
C_old,newandC_newto return before using the new rules for decision-making.
Assume the leader can crash at any point during the cluster membership change. There are three possibilities:
- Leader crashes before
C_old,newis committed - Leader crashes after
C_old,newis committed but beforeC_newis initiated - Leader crashes after
C_newhas been initiated
Illustration:
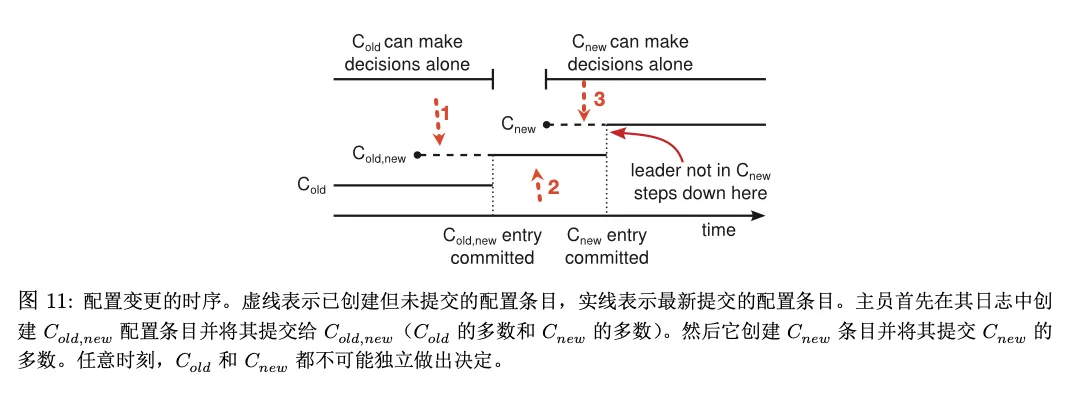
1. Leader crashes before C_old,new is committed
- The cluster hasn’t actually entered joint consensus state (because it hasn’t been guaranteed that both old and new majorities have accepted it)
- Some nodes may have received
C_old,new - Some nodes haven’t received it yet
- Some nodes may have received
There are two sub-cases:
- The new leader doesn’t have
C_old,new:- The latest configuration is still
C_old. If it gets a majority of the old configuration, it can be elected (meaning the configuration change failed, and the system reverts to the old configuration) - But this guarantees no split brain, because joint consensus hasn’t been entered at all — correctness is still preserved
- The latest configuration is still
- The new leader has
C_old,new:- The latest configuration is
C_old,new. It then proceeds according to joint consensus rules: to be elected, it needs a majority of both old and new configurations. After becoming leader, it continues to push this configuration change forward:- Continues replicating
C_old,new - If eventually both old/new majorities accept it,
C_old,newcan be committed - Then continues to send
C_new
- Continues replicating
- The latest configuration is
2. Leader crashes after C_old,new is committed but before C_new is initiated
- The cluster has formally entered joint consensus state (
C_old,newhas been committed — both old and new configuration majorities have accepted it)- At this point, it’s no longer possible to revert to a world governed only by old rules
When a new election begins, a candidate must have C_old,new to be elected.
At this point, the system can continue processing commands, but the commitment of normal command logs must also satisfy majorities in both old/new configurations
3. Leader crashes after C_new has been initiated
The leader has already sent out C_new; some nodes have received it, some haven’t.
- For nodes that have received
C_new:- Act according to new configuration rules
- For nodes that haven’t received
C_new(latest configuration isC_old,new):- Act according to joint consensus rules
Each node always uses the latest configuration in its own log
When the leader crashes:
- A node with
C_newis elected:- Continues according to
C_newrules - Replicates
C_newto other nodes - Eventually commits
C_new
- Continues according to
- A node without
C_newis elected:- It still acts according to joint consensus rules
- If it needs to transition to the new configuration, this new leader appends a new
C_newentry - The previous uncommitted
C_newthat conflicts with the current log may later be overwritten
Several supplementary rules for cluster membership changes:
-
When adding a node, synchronize logs first, then start the membership change: the new node doesn’t have voting rights until its log is caught up, and doesn’t participate in log counting (read-only state). Otherwise, the new node would be too far behind, slowing down replication and potentially affecting normal command commitment.
-
When removing a node, the leader itself may also be removed from the cluster: if
C_newno longer includes the current leader, then afterC_newis committed, it should step down. -
Removed old nodes may send spurious vote requests: because they can’t receive the new leader’s heartbeats, they’ll time out, increment their term, and send RequestVotes. Although they can’t get elected, they may disrupt the current cluster.
Common handling: If a node has recently confirmed there’s a leader in the cluster (e.g., received a valid heartbeat from the current leader within the minimum timeout), it rejects such disruptive vote requests.
Single-Server Change#
The above approach is the original paper’s joint consensus.
But in many engineering implementations, a more common approach is: add or remove only one node at a time.
Reason:
- When only changing one node, the old/new majorities naturally overlap
- So there can’t be two completely independent valid leaders
For example:
- Old:
{a,b,c} - New:
{a,b,c,d}
Here:
- Old majority:
2/3 - New majority:
3/4
A majority in the new configuration can’t be completely disjoint from a majority in the old configuration, so there’s no split brain.
Result of single-server change:
- New leader has
C_new: continue pushing the change forward - New leader doesn’t have
C_new: change fails, revert to old configuration
Single-server change is simpler, easier to implement, and sufficient for most scenarios.
Disadvantages of single-server change:
-
Replacing a machine takes two steps
{a,b,c}→{a,b,c,d}→{d,b,c}
-
Passes through an even-numbered node phase
- e.g., expanding from 3 to 4 nodes
- If a
2:2network partition occurs, no leader can be elected
-
Two consecutive changes with a leader switch in between can cause errors
- Solution: the new leader first commits a
no-opentry from its own term - Then starts the next configuration change
- Solution: the new leader first commits a
Log Compaction#
If Raft runs for a long time, logs keep growing. If they’re never cleaned up:
- Increasing disk/memory usage
- Node restart recovery gets slower and slower
- Log catch-up for lagging followers also gets slower
Raft’s approach: snapshot
- Save the state machine result at a certain point in time
- Then delete the logs from before that point that are already included in the snapshot
In other words, the node retains:
- One snapshot
- New logs after the snapshot
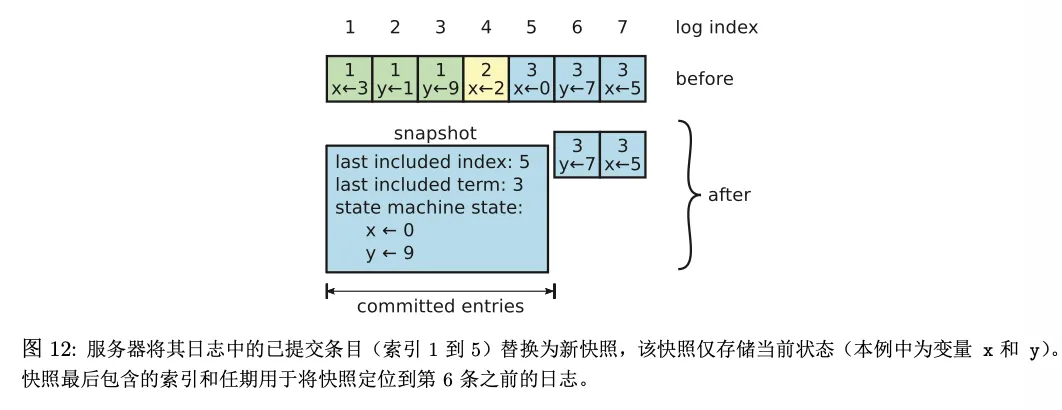
In addition to state machine data, the snapshot must also record:
lastIncludedIndexlastIncludedTerm
Because:
- After compaction, earlier logs are deleted
- But Raft still needs to know: which log position does the snapshot cover up to, and what was the term at that position
Logs are deleted because they’ve already been:
- Committed
- Applied to the state machine
Since the state machine result is already preserved in the snapshot, there’s no need to keep every individual historical log entry.
If a follower lags so far behind that the leader has already deleted the old logs it’s missing, then:
- The leader can’t use AppendEntries to fill them in one by one
In this case, the leader directly sends:
InstallSnapshot RPC
In other words: instead of filling in old logs, directly send the snapshot. The follower restores state from the snapshot, then continues replicating subsequent logs.
Read-Only Operation Handling#
Intuitively:
- Read requests can go directly to the leader
But this isn’t necessarily linearizable reads.
Because:
- The leader may have been disconnected from the majority
- The majority may have elected a new leader
- If the old leader directly returns local state, it could serve stale data to the client
The safest approach for strongly consistent reads is to treat “reads” as log entries going through consensus — this is definitely safe, but costly.
A safer approach:
To achieve strongly consistent reads, several conditions must be met:
- Read requests must go to the leader
- The leader must have committed at least one log entry in its current term
- Otherwise it can’t be sure which previous logs have truly been committed
- This is usually solved by committing a
no-opentry
- Before reading, the leader must confirm it’s still the leader
- Approach: send a round of heartbeats and get responses from a majority
- The leader records its committed log index as
readIndex- As long as the state machine has applied up to
readIndex - It can safely read and return
- As long as the state machine has applied up to
If strong consistency isn’t required, a common approach:
- Follower receives a read request
- Requests
readIndexfrom the leader - Follower waits until its own state machine has applied up to that position
- Then returns the result
This distributes read pressure, but semantically it’s no longer “direct local reads.”
Performance and Optimization#
In the ideal case, Raft commits a log entry with a minimum of:
- One AppendEntries RPC round trip (which is already efficient enough)
Main factors affecting performance:
-
Election timeout
- Incorrect settings affect leader switch speed and stability
-
Batch
- Multiple commands can be included in one log entry for batch replication
- Saves network overhead
-
Pipeline
- The leader doesn’t need to wait for one RPC reply before sending the next
- Can continuously push logs
-
Slow followers don’t affect overall commit
- As long as a majority of nodes are functioning, Raft can continue committing
Comparing Raft and Paxos:
Raft doesn’t allow log holes, so it’s more conservative in log structure than many Paxos variants. Actual performance depends on the specific implementation and workload.
- Here, Paxos refers to a consensus algorithm that can perfectly handle all edge cases caused by log holes while ensuring the cost of handling these edge cases is less than the benefit of allowing log holes.
- Raft does have a performance ceiling due to disallowing log holes, but most systems don’t even come close to reaching Raft’s ceiling. So there’s no need to worry about Raft’s inherent bottlenecks.
- A modified Raft that allows log holes → ParallelRaft.