状态机:
- 有一份内部状态
- 外界给它一个命令
- 它按照规则更新状态,并返回结果
即: 一个按照输入命令不断演化内部状态的系统
复制状态机: 被复制出来的多个状态机副本 — replicated state machines(被复制的状态机们)
这个名字看起来很不直观,因为它强调的是一个抽象模型,并不是一个具体实现。
似乎也可以叫做「多副本命令同步系统」,但过于贴近实现,复制状态机更强调问题抽象
复制状态机 = 很多台机器,各自维护一份相同的“业务对象”,并且通过执行同一串命令,让它们始终保持一致。
相同的初始状态+相同的输入=相同的结束状态
但似乎这个描述本来就很直观,但直观并不代表可作为系统设计模型,我们可能已经默认了:
- 状态机是确定性的
- 节点初始状态一样
- 命令输入一样
- 命令顺序一样
- 节点不会中途乱执行别的东西
我们需要将这种直观变得更严谨,这样论文后续才能围绕展开:
即:
- 只要我保证日志一致
- 就能保证命令顺序一致
- 就能保证状态一致
也就是在做转化:分布式一致性问题 -> 复制状态机问题 -> 日志一致性问题
论文中对于raft共识算法的简要总结:

状态简化#
论文原图:
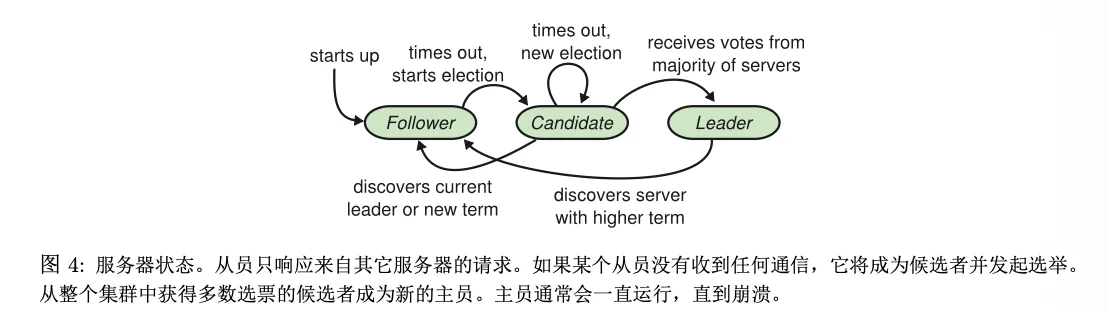
对于三种状态之间的轮转:
- follower: 当Election timeout时,将自己变为 candidate,经过选举决定是成为 leader还是 follower
- Leader:当leader 看到了一个
比自己 term 更大的消息,会切回 follower- leader宕机:直接挂了,恢复回来变为 follower
- leader网络隔离:它自己可能还以为自己是 leader,但集群其他节点会超时并选出新 leader;等这个旧 leader 之后看到更大 term,它才会退回 follower
- 论文之外的,一些自定义的让 leader退位的实现
任期: 作为 raft算法中的时间线,每一段任期都从一次选举开始!保证每次选举出的 leader<=1个
通过任期可以帮助我们确认一台服务器的历史状态
raft中的服务器之间通过RPC来进行通信,这里的两种主要的RPC:
- RequestVoteRPC:候选者在选举时发起
// 请求投票RPC Request
type RequestVoteRequest struct {
term int // 自己当前的任期号
candidateId int // 自己的ID
lastLogIndex int // 自己最后一个日志号
lastLogTerm int // 自己最后一个日志的任期
}
// 请求投票RPC Response
type RequestVoteResponse struct {
term int // 自己当前任期号
voteGranted bool // 自己会不会投票给这个candidate
}- AppendEntriesRPC:复制日志
// 追加日志RPC Request
type AppendEntriesRequest struct {
term int // 自己当前的任期号
leaderId int // leader(也就是自己)的ID
prevLogIndex int // 前一个日志的日志号
prevLogTerm int // 前一个日志的任期号
entries []byte // 当前日志体,空日志体则为心跳
leaderCommit int // leader的已提交日志号
}
// 追加日志RPC Response
type AppendEntriesResponse struct {
term int // 自己当前任期号
success bool // 如果follower包括前一个日志, 则返回true
}领导者选举#
心跳机制:leader会周期性的向所有的 follower发生心跳,来维持自己的地位。
- 若follower有一段时间没有收到心跳,则会认为没有可用的leader了,开始发起选举:
- follower先增加自己的当前任期号
- 将自己的状态变为 candidate
- 投票给自己,并行的给其他服务器发送投票请求(RequestVoteRPC)
投票可能会有三种结果:
- 该节点获得超过半数的选票赢得选举->成为 leader开始发送心跳
- 其他节点赢得选举->收到新leader的心跳之后,若新leader任期号>=自己当前的任期号,则将状态变回 follower
- 没有leader->每个 candidate都在一个自己的随机选举超时时间后开始新一轮投票
- 这里没有 leader的原因是有多个 follower同时成为 candidate,得票过于分散,无法获得超过半数选票
若 candidate没有收到超过半数选票,也没有收到新 leader的心跳,则就会在「随机选举超时时间」后再次发起选举,这并不需要各个节点达成共识
日志复制*#
- leader接受到指令后会将指令作为一个新的日志条目追加到日志中去
- leader并行的发送AppendEntries RPC给follower,让他们复制该条目;当 leader 确认该条目已经复制到多数节点后,这条日志就可以被提交;提交后,leader 再把它应用到状态机,并将结果返回给客户端
日志:
- 状态机指令
- leader任期号
- 日志号(日志索引)
需要日志号和任期号两个因素才能唯一确定一个日志
如图:
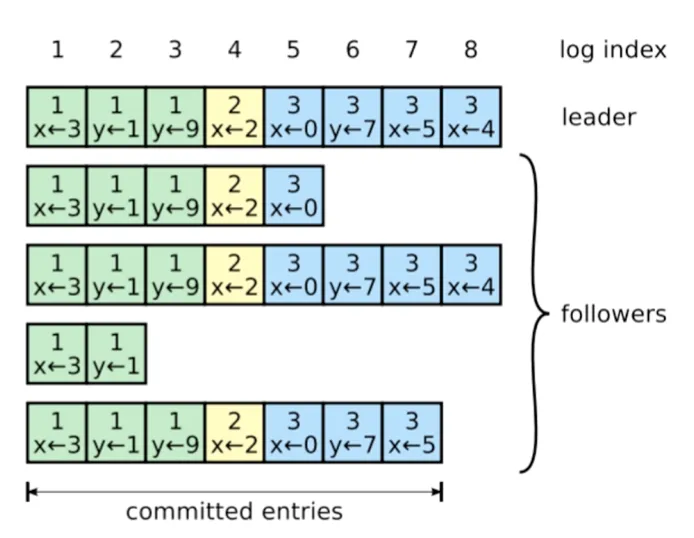
可以从图中看到,这里的部分节点的日志是落后很多的,那么如何让这些节点追上leader,使得最终所有节点的日志是完整且顺序一致的呢?
常见情况有三类:
-
follower 落后 follower 只是慢,并没有宕机。leader 会持续发送 AppendEntries。 如果某条日志已经在多数节点上复制成功,leader 就可以提交并回复客户端; 即使这个慢 follower 还没跟上,也不影响这条已提交日志的安全性。 之后 leader 会继续把缺失日志补给它。
-
follower 宕机后恢复 follower 宕机一段时间后恢复,日志可能缺很多。 恢复后它会重新接收 leader 的 AppendEntries。 如果 prevLogIndex / prevLogTerm 对不上,就说明它当前日志和 leader 不一致; leader 会回退并重试,直到找到双方共同前缀,再从那里开始追加缺失日志。
-
旧 leader 宕机后恢复 旧 leader 宕机前,可能写入过一些未提交日志。 这些未提交日志不保证保留;如果后来新 leader 的日志和它冲突,这些旧日志可以被覆盖。 旧 leader 恢复后会先变成 follower。 当它收到当前 leader 的 AppendEntries 时,如果发现冲突,就会删除自己的冲突后缀,并追加 leader 的日志,最终追平。
补充: 投票阶段会比较 candidate 的最后一条日志(lastLogTerm, lastLogIndex),这里比较的不只是已提交日志,未提交日志也会参与比较。 这样做的目的是避免明显更旧的节点当选。 但“日志更新”不等于“这些未提交日志一定会被保留”; 未提交日志本来就可能在后续被覆盖。
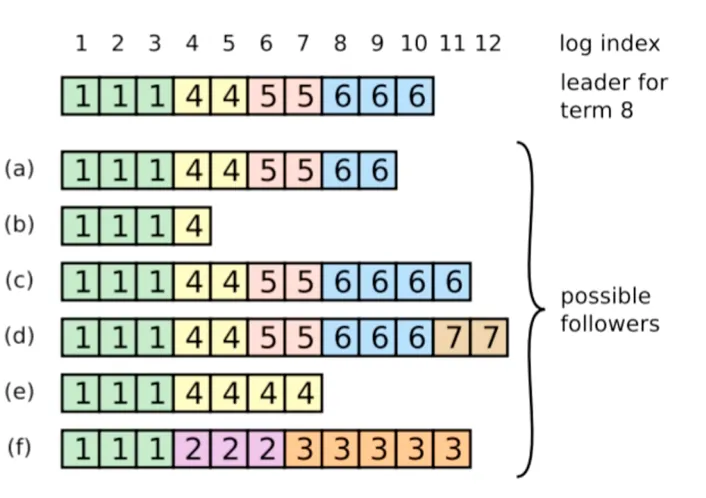
「一致性检查」:leader在发往follower的追加条目RPC中,会放入 前一个日志的索引位置和任期号,若 follower在日志中找不到前一个日志,那么他会拒绝这个日志,leader收到拒绝后会发送前一个日志条目,从而实现 逐步向前定位到 follower第一个缺失的日志位置
当然,这样的方式看起来效率非常的低,实际上是可以优化的,论文中也有说到优化思路,但实际上作者认为这是没有必要的,这样的情况出现场景很少(计算机应用中很多时候都在 trade-off,emmm 各行业也都是这样,所以可以根据需求来动态调整对应的策略)
从上面可以看到:leader 当选之后,不需要专门设计一套“修日志流程”;它只要继续正常发送 AppendEntries,落后或冲突的 follower 就会在一致性检查失败与重试过程中逐步追平
leader 不会为了迁就 follower 去覆盖或删除自己的日志条目;但旧 leader 以后若恢复成 follower,它自己那段未提交且冲突的日志后缀,仍然可能被当前 leader 覆盖
从而保证:
- 只要过半的服务器能正常运行,raft就可以接受,复制并应用新的日志条目
- 新的日志条目可以在一个RPC来回被复制给集群中的过半机器
- 单个运行慢的 follower并不会影响整体性能
对于 AppendEntries RPC:
// 追加日志RPC Request
type AppendEntriesRequest struct {
term int // 自己当前的任期号
leaderId int // leader(也就是自己)的ID
prevLogIndex int // 前一个日志的日志号
prevLogTerm int // 前一个日志的任期号
entries []byte // 当前日志体
leaderCommit int // leader的已提交日志号
}
// 追加日志RPC Response
type AppendEntriesResponse struct {
term int // 自己当前任期号
success bool // 如果follower包括前一个日志, 则返回true
}其中, PreLogIndex 和 PreLogTerm 是来做一致性检查的,只有这两个都与 follower 当中的相同,follower 才会接受这次追加;否则就会拒绝,leader 再向前回退并重试
对 follower 而言,接收到了 leader 日志,还不能立即提交,因为它自己并不知道这条日志是否已经到达多数节点;只有 leader 确认达到多数后,再通过
leaderCommit通知它推进提交
leaderCommit:Leader 会在 AppendEntries RPC 中把这个提交信息告知 Follower(以这个变量的方式)
然后 follower 就可以把自己复制但未提交的日志设置为已提交状态,就可以应用到自己的状态机里了
如果 leader commit > commit index,那么就把 commit index 设置为 min(leaderCommit, index of last new entry)
看起来有点抽象,其实就是:follower 可以把“自己本地已经有的那部分日志”提交到
leaderCommit为止,不能跳过空缺位置,也不能提交自己还没收到的日志
安全性*#
对于领导者选举和日志复制两个问题,实际上已经覆盖了共识算法的全程,但是还不能保证每一个状态机会按照相同的顺序执行相同的命令,所以 Raft 还需要通过补充完善整个算法,使得可以在各类宕机问题下都不出错
- Leader 宕机处理:选举限制
- Leader 宕机处理,新 leader 是否提交之前任期之内的日志条目
- Follower 和 Candidate 宕机处理
- 时间与可用性限制(上面在说随机超时时间的时候,就已经说到了)
如果一个 follower 落后了 leader 若干条日志,而投票时又不去比较日志新旧,那么它就可能在下一次选举中当选;一旦这种更旧的节点成了 leader,就可能把系统带到错误历史上去。因此 Raft 必须在投票阶段限制 candidate 的日志不能比投票者更旧
在 RequestVote RPC 当中,有着这样的限制,如果投票者自己的日志比 Candidate 的还新,那么它会拒绝掉该投票请求
比较「新」的方式:通过比较 LastLogIndex 和 LastLogTerm 两个变量。如果两份日志最后条目的任期号不同,那么任期号大的日志更「新」。如果两份日志最后条目的任期号相同,那么日志号较长的那个更「新」
如图:
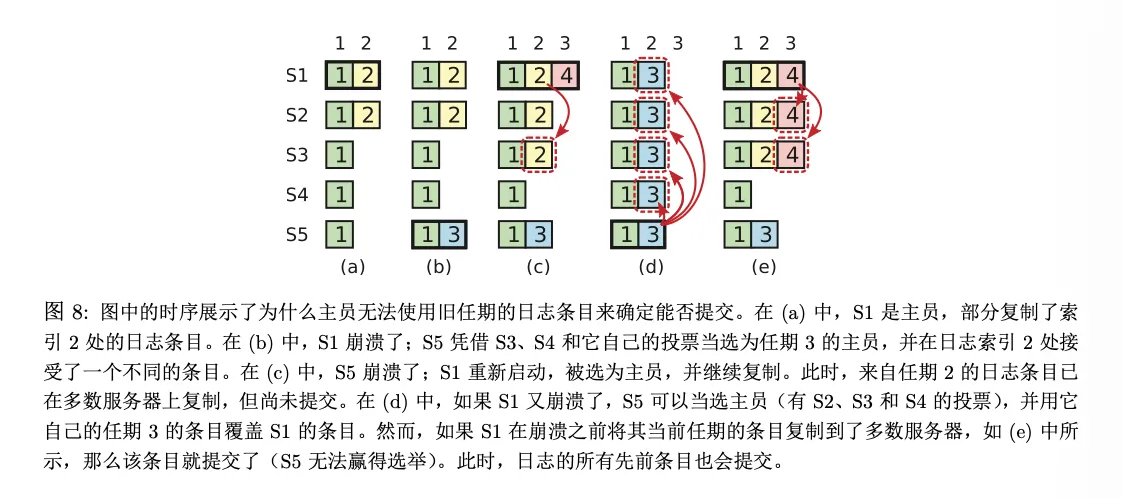
A 当中, S1 是 leader。然后S1 崩溃了, S5 成为 leader。但是 S5 仍然能够凭借 S3 和 S4 的选票成为 leader,到了 B 阶段,接收到了第三任期的日志,到了 C 当中,S5 又崩溃了,S1当选leader,此时日志 2被复制到了多数节点,但还没有被提交,到了d中,S1再次崩溃,S5通过 S2-4的选票当选leader
这里有一个问题:既然这里的 2 号日志已经被复制到了大多数节点,可是仍然被覆盖了,会不会导致不安全的问题?
这里要注意:图里想说明的不是“已提交日志也可能被覆盖”,而是“旧 term 的日志即使已经出现在多数节点上,也还不能仅凭这一点就认定它已经提交”。
如果某条旧 term 日志后来真的被提交了,那么之后任何能当选的新 leader 都必须包含它,已提交日志不会再被覆盖。真正可能被覆盖的,是那些尚未提交的旧 term 日志。所以:
leader 不能只靠“多数副本”提交旧 term 的日志;leader 只能用“当前 term 的日志达到多数”来推进提交。
而一旦当前任期日志提交,它前面的旧日志也会一起提交。
对于 follower 和 candidate 当机的处理:
如果 follower 或 candidate 崩溃了,那么后续发送给他们的 RequestVote 和 AppendEntries RPC 都会失败。Raft 通过不断重试来处理这种失败。如果崩溃的机器重启了,那么这些 RPC 就会成功地完成;如果一个服务器在完成了 RPC,但是还没有响应的时候崩溃了,那它重启之后就会再次收到同样的请求。(Raft 的 RPC 都是幂等的)
示例#
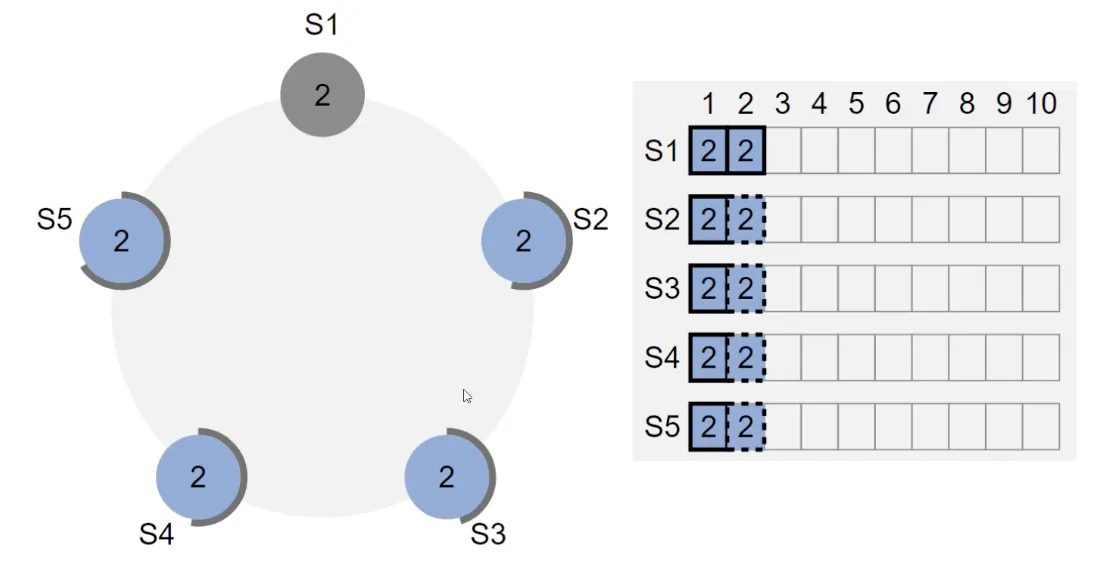
设想一个这样的场景,现在有 5 个服务器,最开始他们 5 个都是 follower,由 S1 最先超时,拿到先发优势,成功当选 leader。S1 当选 leader 之后,就会向所有的服务器开始发送心跳,现在 S1 发送日志 1 到S2-5,S1收到的sccess 达到多数的时候,S1 本地提交,然后S1的下一个心跳将信息传递给了 follower,所有节点都提交了
这个时候我们再向 S1 发送一个请求, 当 S1 收到了其他机器的回复之后,在本地提交。然后 S1 在这个时候宕机了,其他的机器的第二个日志无法进行提交
在经过选举超时,重新选出 leader S3之后,尽管 S3 会一直发送心跳,但是日志 2一直无法被提交(因为 S3 这个时候的任期是 3,Leader 只能用当前任期的日志达到多数来提交,对于任期为 2 的日志,无法提交,只能靠后续日志的提交,将旧日志一并提交)
这个时候我们向 S3 发送请求,我们会发现,随着新日志的提交,老日志也提交了(日志 2 和日志 3 是同一时间提交的,也就是在同一个时间变为实线框的)
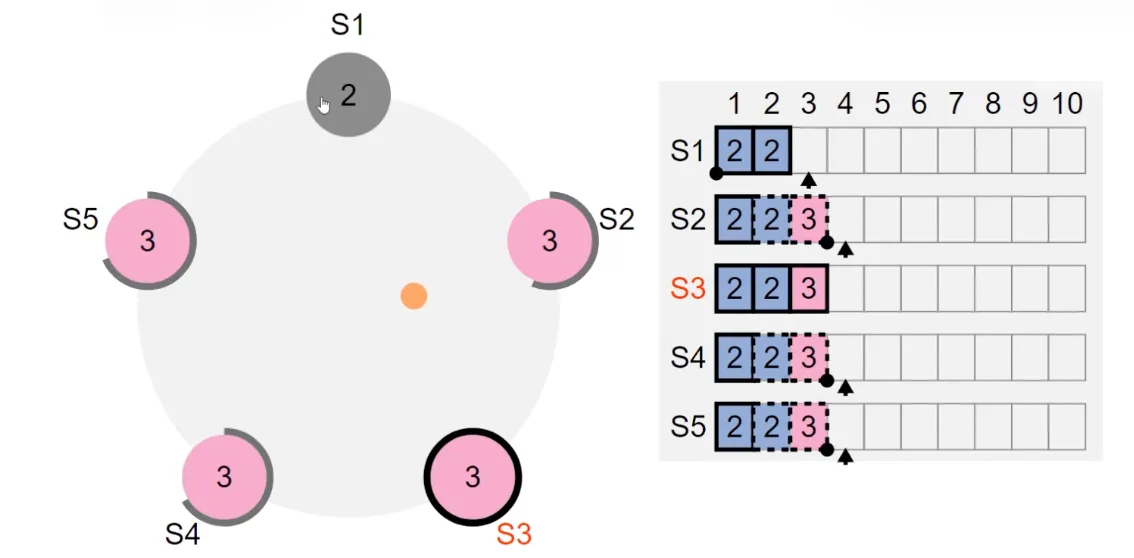
其实想说明的就是,当前任期只能提交当前任期的日志,对于之前任期的日志,只能在后续日志提交的时候,一并被提交
集群成员变更#
多成员变更#
对于老配置集群和新配置集群,可能会出现两个 leader 的情况(脑裂),所以的话,为了解决这样的问题:

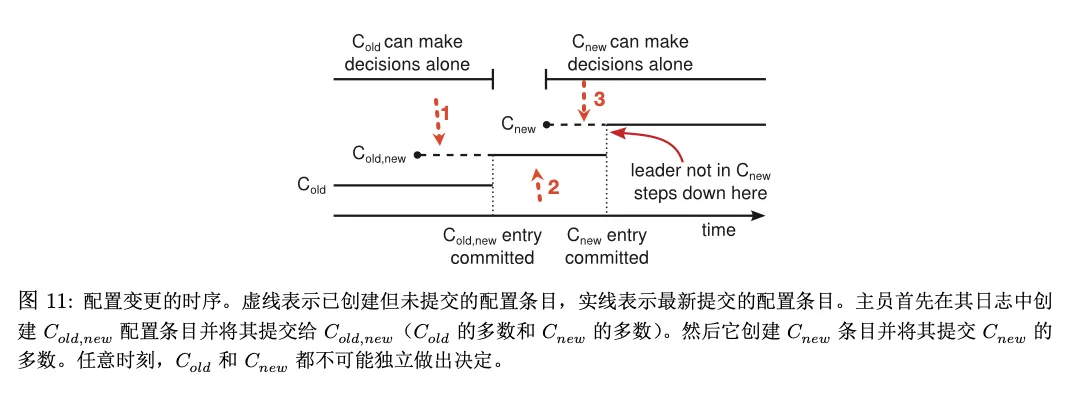
采用两阶段的办法:集群先从老配置切换成一个过渡的配置(联合一致),再切换到新配置
所以问题就变成了如何在联合一致的状态,避免发生脑裂问题 配置信息作为一个日志体,包装为一个普通的 AppendEntries RPC发送给所有的 follower
- 第一阶段,Leader 发起C old new使整个集群进入联合一致状态。这个时候所有的 RPC 都要在新旧两个配置当中都达到大多数才算成功
- 第二阶段,Leader 发起 C New,使整个集群进入新配置状态。这个时候所有的 RPC 只要在新配置下能够达到大多数,就算成功
一旦某个服务器将新配置加到自己的日志当中,它就会用最新的配置来做出未来所有的决定。无论该配置是否被提交,服务器总是使用日志中最新的配置。这意味着 leader 不用等待,C old new 和 C new 返回,就会直接用其中的新规则做出决策
假设 leader 可以在集群成员变更任何时候宕机,有以下三种可能:
- Leader 在 C old New 未提交时宕机
- Leader 在 C old new 已提交但 C new 未发起时宕机
- Leader 在 C New 已发起时宕机
如图:
- Leader 在
C old,new未提交时宕机
- 集群还没有真正进入联合一致状态(因为还没有保证 old 多数和 new 多数都接受了它)
- 有些节点可能已经收到了 C old,new
- 有些节点还没收到
%% - 这时如果新 leader 没有
C old,new,那就按C old继续选举和运行
- 配置变更可能失败,但不会脑裂
- 如果新 leader 具有
C old,new,那它后续就按联合一致规则继续推进 %%
这个时候还会有两种情况:
- 新 leader 没有 C old,new:
- 最新的配置仍然是C old,如果拿到 old 配置多数,就可以当选(意味着配置变更失败,系统退回旧配置继续运行)
- 但是保证了不会出现脑裂,因为根本还没有进入联合一致状态,仍然保证了正确性
- 新 leader 具有 C old,new
- 最新配置为 C old new,之后按照联合一致规则继续推进,即达到「old 配置多数」&&「new 配置多数」则可以当选,当选leader后(继续推进这次配置变更):
- 把 C old,new 继续复制出去
- 如果最终 old/new 两边都达到多数,C old,new 就可以提交
- 再继续发 C new
- 最新配置为 C old new,之后按照联合一致规则继续推进,即达到「old 配置多数」&&「new 配置多数」则可以当选,当选leader后(继续推进这次配置变更):
- Leader 在
C old,new已提交但C new未发起时宕机
- 集群正式进入联合一致状态(C old,new 已经提交了。即 old 和 new配置的多数都接受了他)
- 这个时候就不再能退回以 old规则为主的世界了(可以看上面图的上方 old&new范围)
开启新一轮选举后,candidate想要当选,就必须满足新 leader 一定也具有 C old,new
这时系统可以继续处理命令,但普通命令日志的提交,也要同时满足 old/new 两边多数
- Leader 在
C new已发起时宕机 Leader 这个时候已经将 Cnew 发出去了,有的节点收到了,有的节点没有收到
- 对于已经收到 C new 的节点
- 按照新配置规则行动
- 还没收到 C new 的节点(最新配置为 C old new)
- 按联合一致规则行动
每个节点总是使用自己日志中最新的配置
当leader挂了以后:
- 具有 C new 的节点当选
- 继续按 C new 规则推进
- 把 C new 复制给其他节点
- 最终让 C new 提交
- 不含C new 的节点当选
- 它仍然按联合一致规则行动
- 如果后续需要推进到新配置,就由这个新 leader 自己再追加一条新的
C new - 之前那个未提交、且与当前日志冲突的
C new,后续可能被覆盖
集群成员变更的几个补充规则:
-
新增节点时,先同步日志,再开始成员变更,
- 让新节点在同步完成日志前不具备投票权,不参与日志计数(只读状态)
- 否则:新节点太落后,会拖慢复制。还可能影响正常命令提交
-
缩减节点时,leader 自己也可能被移出集群
- 如果
C new里已经没有当前 leader - 那么
C new提交后,它就应该主动退位
- 如果
-
已出群的旧节点可能会乱发投票请求
- 因为它收不到新 leader 的心跳
- 会超时、term 增长、发送
RequestVote - 虽然它选不上,但可能扰乱当前集群
常见处理:如果一个节点最近还确认集群里有 leader(例如在最小超时时间内收到了当前 leader 的有效心跳),就拒绝这类干扰性的投票请求
单节点变更#
上面的做法是论文原版的 joint consensus
但在很多工程实现中,更常见的是:一次只增减一个节点
原因:
- 只变一个节点时,old/new 的多数天然有交集
- 所以不会出现两个完全独立的合法 leader
例如:
- old:
{a,b,c} - new:
{a,b,c,d}
此时:
- old 多数:
2/3 - new 多数:
3/4
new 配置里的多数,不可能和 old 配置多数完全无交集,所以不会脑裂
单节点变更的结果:
- 新 leader 具有
C new:继续推进变更 - 新 leader 不具有
C new:变更失败,退回旧配置
单节点变更简单,更好实现,且大部分场景够用
单节点变更的缺点:
-
机器替换要两步
{a,b,c}->{a,b,c,d}->{d,b,c}
-
会经过偶数节点阶段
- 例如 3 节点扩成 4 节点
- 如果例如发生
2:2网络分区,就选不出 leader
-
连续两次变更 + 中途切主,可能出错
- 解决方法:新 leader 先提交一条自己任期内的
no-op - 再开始下一次配置变更
- 解决方法:新 leader 先提交一条自己任期内的
日志压缩#
raft 运行时间久了,日志会不断增长
如果一直不清理:
- 占用越来越多的磁盘/内存
- 节点重启恢复越来越慢
- 落后 follower 追日志也越来越慢
raft 的做法是:快照(snapshot)
- 把某一时刻状态机的结果保存下来
- 然后删除这之前已经包含进快照的日志
也就是说,节点之后保留的是:
- 一份快照
- 快照之后的新日志
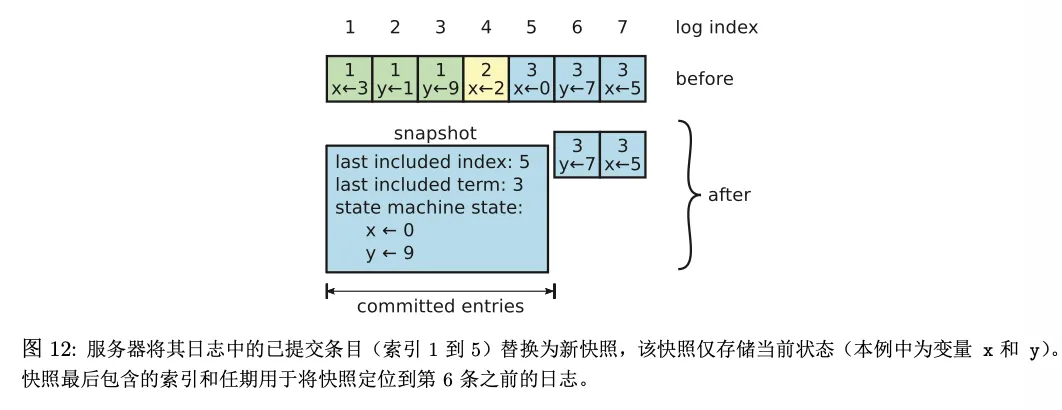
快照除了状态机数据之外,还必须记录:
lastIncludedIndexlastIncludedTerm
因为:
- 压缩后,前面的日志被删掉了
- 但 raft 仍然需要知道:快照最后覆盖到哪个日志位置,以及那个位置的任期号
删日志的场景:因为这些日志已经:
- committed
- applied 到状态机
既然状态机结果已经保存在快照里,就不需要再保留它们的每一条历史日志
如果一个 follower 落后太多,以至于 leader 已经把它缺失的旧日志删掉了,那么:
- leader 没法再用 AppendEntries 一条条补
这时 leader 会直接发:
InstallSnapshot RPC
即:不再补旧日志了,直接把快照发过去,follower 用快照恢复状态,再接着复制后续日志
只读操作处理#
直觉上看:
- 读请求直接去 leader 读就行
但其实这不一定是线性一致读
因为:
- leader 可能已经和多数派断开
- 多数派可能已经选出了新的 leader
- 旧 leader 如果直接返回本地状态,就可能把旧值读给客户端
强一致读最稳妥的做法就是把“读”也当作一条日志走共识,这样一定安全,但成本高
更稳妥的做法:
要做到强一致读,需要满足几个条件:
- 读请求一定发给 leader
- leader 在自己任期内至少提交过一条日志
- 否则它不能确定之前哪些日志已经真正提交
- 通常可以通过提交一条
no-op来解决
- leader 在读之前,要确认自己仍然是 leader
- 做法:发一轮心跳,拿到多数节点回复
- leader记录自己已提交的日志号为
readIndex- 只要状态机已经 apply 到
readIndex - 就可以安全读取并返回
- 只要状态机已经 apply 到
如果不要求强一致,常见办法:
- follower 收到读请求
- 向 leader 请求
readIndex - follower 等自己 apply 到这个位置
- 再返回结果
这样可以分担读压力,但语义上已经不是“直接本地随便读”
性能和优化#
理想情况下,raft 提交一条日志,最少只需要:
- 一轮 AppendEntries RPC 来回(其实已经足够高效)
影响性能的主要因素:
-
选举超时
- 设置不合理会影响切主速度和稳定性
-
Batch
- 一次日志里可以带多个命令,然后批量进行复制
- 节省网络开销
-
Pipeline
- leader 不必等上一个 RPC 回复后,才发下一个
- 可以持续推送日志
-
慢 follower 不影响整体提交
- 只要多数节点正常,raft 就可以继续提交
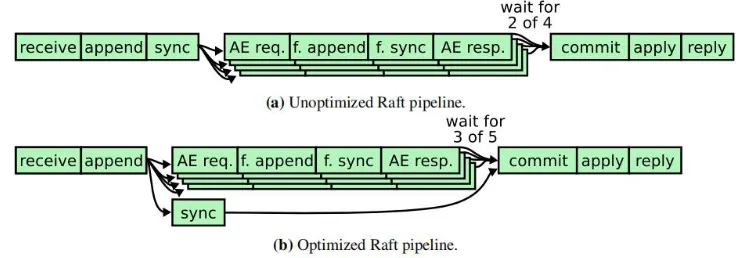
Raft与Paxos比较:
raft 不允许日志空洞,所以它在日志结构上比很多 Paxos 变体更保守;至于真实性能,还要看具体实现和工作负载
- 这里的Paxos,实际上指的是一个能完美处理所有日志空洞带来的边界情况,并能保证处理这些边界情况的代价,要小于允许日志空洞带来的收益的共识算法。
- raft确实有不允许日志空洞这个性能上限,但大部分系统实现,连raft的上限,都是远远没有达到的。所以无需考虑raft本身的瓶颈。
- raft允许日志空洞的改造 -> ParallelRaft。