抛硬币#
HyperLogLog 的核心思想来自一个巧妙的类比:连续抛硬币,直到出现正面为止,记录抛掷次数。如果多轮实验下来,最多的一次抛了 kmax 次才出正面,那么大概可以反推出总共做了大约 2kmax 轮实验。把这个思路搬到数据统计上:先把存入的 value 通过 hash 函数转为比特串(Redis 使用 64 位 hash,能表示的范围为 264−1),0 代表硬币的反面,1 代表正面。那么只需要记录所有数据中”第一次出现 1 的最大位置 kmax“,就能估算出存入了多少条数据。参考:juejin ↗。
Redis 中的 HyperLogLog#
在 Redis 中,HyperLogLog 的参数设置为:m=16834(桶数),p=6,L=16834×6。总占用内存为 16834×6÷8÷1024=12K。
存入数据时,value 会被 hash 成 64 位的比特串。前 14 位(14=log2m)用来定位桶,将其转为十进制就是桶标号。完整的比特串是 64 位,去掉前 14 位后剩余 50 位。最极端的情况下,第一个 1 出现在第 50 位,此时 index=50,转为二进制是 110010,可以被存入桶中。
不同的 value 可能被分到同一个桶(前 14 位相同),但后续比特串中第一个 1 出现的位置可能不同。此时会比较新旧 index:新的 index 更大就替换,否则保持不变。就这样,一个 key 对应的 16384 个桶都被设入了各个 value,每个桶保留一个 kmax。当调用 pfcount 时,根据前面所说的估算方式,就可以计算出这个 key 大概被设置了多少次 value。HyperLogLog 用仅仅 12K 的存储空间就能统计多达 264 个不同的值。
基数估计#
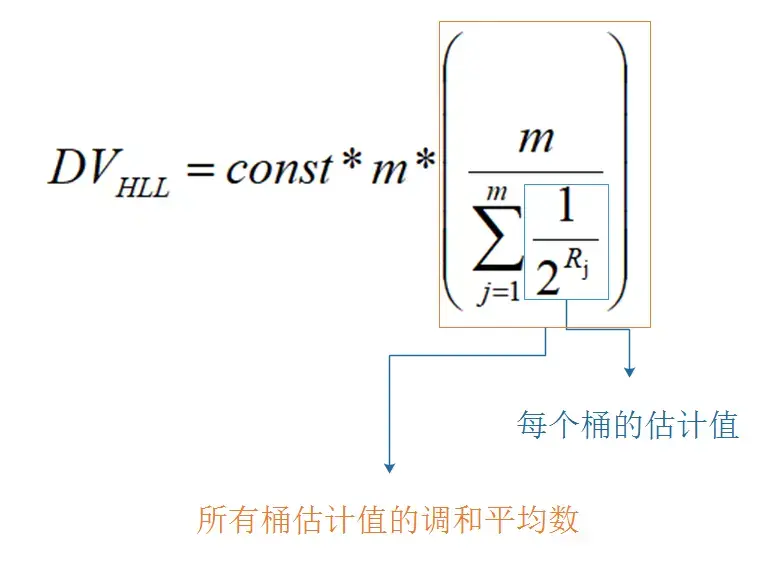
那么具体如何从多个桶的 kmax 估计出总基数?直觉上可以对所有桶的 kmax 取平均,即普通平均数:m∑i=1mkmaxi。但平均数容易受极端值影响,HyperLogLog 实际使用的是调和平均数。令 m 为桶数,R 为调和平均数 Hn=∑i=1nxi1n,初步拟定的估计公式为:
DVLL=constant×m×2R^
最终的统计公式中还引入了常数修正因子,以修正小基数和大基数下的偏差。
n=2kmax 的推导#
以下推导详细说明了前面” n≈2kmax “这个估计是怎么来的。
一、伯努利试验的定义及概率 P(k) 的含义#
伯努利试验被定义为”连续抛硬币,直到出现正面为止,记录所需的抛掷次数”。这里的”伯努利试验”实际上属于几何分布的范畴。具体来说:
二、极大似然估计的推导过程#
1. 问题建模#
2. 对数似然函数#
为了简化计算,对概率取自然对数:
L(n)=ln([1−2m1]n−[1−2m−11]n)
3. 泰勒展开近似#
当 m 较大时,2m1 非常小,可以利用近似 1−x≈e−x(泰勒展开的一阶近似):
1−2m1≈e−2m1,1−2m−11≈e−2m2
代入后,概率简化为:
P(kmax=m∣n)≈e−2mn−e−2m2n
4. 最大化似然函数#
令 x=2mn,则概率表达式变为:
P≈e−x−e−2x
对 x 求导并令导数为零:
dxd(e−x−e−2x)=−e−x+2e−2x=0
解得:
e−x=2e−2x⇒ex=2⇒x=ln2
因此:
2mn=ln2⇒n=ln2⋅2m≈0.693⋅2m
5. 工程近似#
在题目中,常数因子 ln2≈0.693 被忽略,简化为:
n≈2kmax
这是因为:
- 数量级匹配:当 m 较大时,0.693⋅2m 与 2m 处于同一数量级。
- 整数估计:实际应用中 n 需为整数,取 2m 更简洁。
三、直观验证#
示例:当 kmax=3 时#
四、总结#
- 伯努利试验的概率:单次试验抛掷 k 次的概率为 P(k)=2k1。
- 极大似然估计:通过最大化观察到 kmax=m 的概率,推导出 n≈2m。
- 工程简化:忽略常数因子 ln2,得到直观的整数关系 n=2kmax。
